word2vec
之前介绍了词袋模型,词袋模型是一种用向量表示句子的方法,像这样把一段文本转换成数值形式,就称为词嵌入(word embedding),除了词袋模型之外还有很多方法可以对文本进行转换,现在就来介绍另外一种非常著名的方法word2vec。
之前就提到了,通过词袋模型表示句子并没有考虑到词与词之间的联系,同时需要注意的是,如果我们用词袋法表示一个词,就相当于独热编码的方法,会产生一个稀疏矩阵。而我们现在要介绍的word2vec,首先,它可以表示一个词,而且可以用一个远比词汇表小的向量去表示,另一方面,它也考虑了词与词之间的关系,总的来说,就是比词袋法好。
word2vec的一个优点就是考虑了一个句子中词与词之间的关系,关于两个词的关系亲疏,word2vec从两个角度去考虑。第一,如果两个词意思比较相近,那么他们的向量夹角或者距离(比如欧几里得距离)是比较小的,举个例子,"king"用(0,1)表示,"queen"用(0,1.1)表示,那么他们的距离就是0.01,这就意味着两者是有很大关联的。第二,如果两个词意思比较接近,那么他们也有更大的可能出现在同一个句子中,甚至两个词可以相互替换句子的意思也不会改变。基于这两点,word2vec就提出了两种具体的语言模型:skip-gram模型和CBOW(连续词袋)模型。
首先以skip-gram为例详细分析一下word2vec的思想。
第一步是基于语料库构建词汇表(语料库就是句子集合,所以单词会重复,但是词汇表没有重复),比如我们从语料库中抽出10000个单词构建词汇表,然后会通过one-hot编码把单词表示成向量,这样每个单词都是一个10000维的向量,向量的每个维度的值只有0和1。
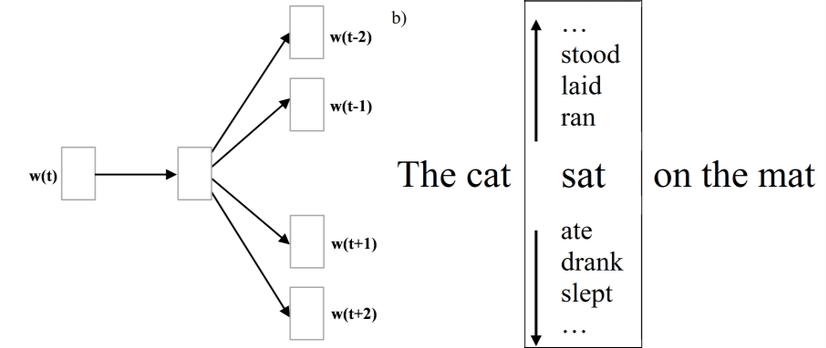
把单词表示成向量之后,skip-gram就构建了这么一个语言模型,一个单词出现在一个句子中,那么这个单词就是和它的上下文有联系的,因此,我们可以通过一个单词以及语料库,推导它最可能的上下文,比如我们有单词"是",同时我们的语料库有"今天"、"开心"、"星期一",如果我们要推断"是"的前后文,很容易就能知道答案是:"今天是星期一"。
根据以上的语言模型,我们可以构建一个神经网络,它的输入就是一个单词的向量,输出就是词汇表中各个单词是前后文的单词的概率,一般来说,这个神经网络包含一个输入层、线性隐层(不含激活函数)、输出层(softmax函数)。通过训练我们的模型,我们就能得到一个能够通过一个词预测它的前后文的语言模型。
还记得我们最初的目标吗,我们希望构建一个词向量,能够表示词与词之间的关系,同时也不会过于稀疏,那么我们怎么从这个语言模型中得到我们的向量,答案就是神经网络中的隐层。
在解释为什么答案和隐层有关之前,我们先来想象一下,我们的神经网络计算输出的各个概率的时候,对输出层来说,它只考虑了上一层的输出作为输入,在这里,也就是隐层的输出,换句话说,假如我们的隐层输出一个300维的向量给输出层,它和我们最初的10000维向量,对于整个模型的输出是等效的,因为这个300维的向量就是最初的10000维向量经过线性变换得到的,所以,我们完全可以用这300维的向量,去表示最初的向量。
为什么这个方法得到的向量会考虑到单词之间的联系,我们可以这样去考虑,假如有两个词,他们的前后文的非常接近,那么他们训练得到的向量应该也是非常接近的,比如"he"和"she"的前后文就可能非常相似,表示的向量也应该非常接近。
最后,再从另一个角度去看待一下这个模型,现在我们有几个句子:"他很好因为他帮助了我"、"我觉得他很有礼貌很好",什么是"好"我们很难定义,但是通过"帮助"、"礼貌"等关键词就能反映出"好"这个概念,这时候我们就不再需要研究如何去定义"好"了,我觉得这也是为什么可以通过句子去表达一个单词的意思。
以上是关于skip-gram的简单介绍,除了skip-gram,我们还有cbow模型,cbow就是从另一个方向构建的语言模型:通过前后文去推断目标词。
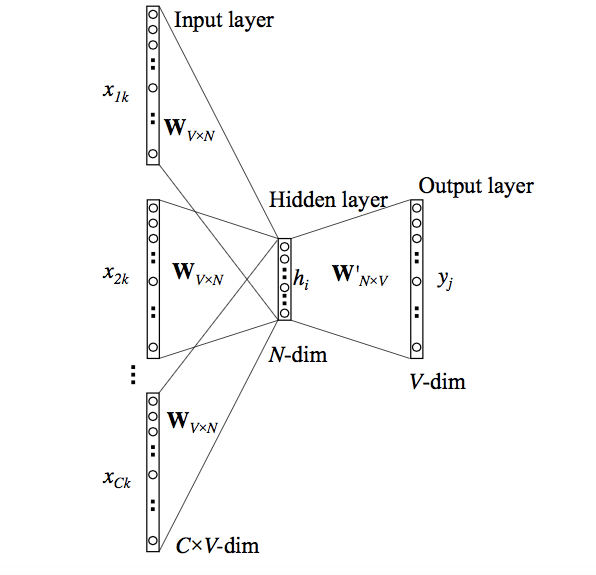
模型的输入是前后文的各个单词对应的向量,输出是词汇表,每个元素都是对应的单词的概率,其实就是把skip-gram反过来,理解了skip-gram,cbow模型也就不难理解了。
不论是skip-gram还是cbow,我觉得它们的核心都在于构建一种单词和前后文之间的关系,然后不断的拓展,在模型的训练过程中逐渐完善这种单词与单词之间的关系,因为这种关系归根到底就是通过单词向量的距离和夹角反映的,所以最后,这两个模型都是得到各个单词在空间中的合理位置,就像最开始那副图。