transformer
在介绍self attention时也提到,用CNN、RNN处理序列数据的时候,无法很好地进行并行计算,同时也会存在信息的丢失,因而transformer就选择直接舍弃CNN、RNN,完全由attention机制构成。
学习一个模型,我觉得最重要的是首先要明白模型要做什么,以及它为什么这样做,对transformer来说,它本质上还是一个encoder-decoder(seq2seq)模型,在之前提到的常规seq2seq结构是由两个RNN(LSTM)加上注意力机制构成的,而现在transformer就是为了解决RNN在处理序列时的不足,而选择把seq2seq中的RNN结构也替换成attention。
我们来一个个分析transformer的结构,首先来回顾一下之前已经介绍过self attention,这里直接给出它的表达式:
可以看到,这里的self attention采用点积的方式计算相似度,主要是点积能转化为矩阵运算,计算速度更快,然而点积也有一个问题,当dk太大时,点积计算得到的内积会太大,这就导致softmax的结果不是0就是1,所以我们需要处一个根号dk进行缩放,这种归一化的手段在构建模型的时候非常常见。
但事实上,transformer不仅仅是用self attention那么简单,而是使用了multi-head attention,而实际上这可以说是self attention的升级版,它是由多个self attention构成:
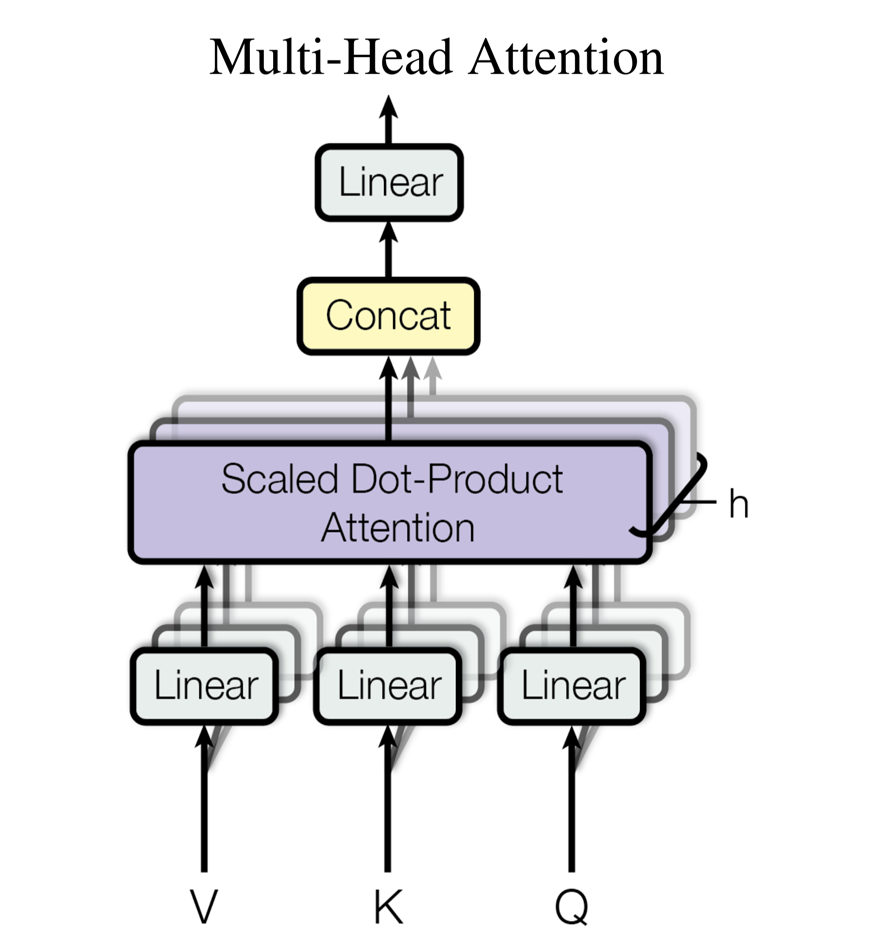
从上图的结构和公式就能看出,其实multi-head attention就是对同样的词向量,从多个角度(乘以不同的WQ、WK、WV得到多个Q、K、V)进行多次self attention,正如原来所说的,self attention之所以基于一个词向量构建出三个新的向量QKV,是为了在解决问题时根据目的更灵活地计算,而现在我们进行多个self attention,就可以理解成我们希望从多个角度去分析问题,得到不同的输出作为不同的理解,最后结合起来,或者说增强了模型捕获不同的信息的能力,所以我们就可以看到,multi-head attention最后也会把不同的self attention计算结果合并到一个张量中。
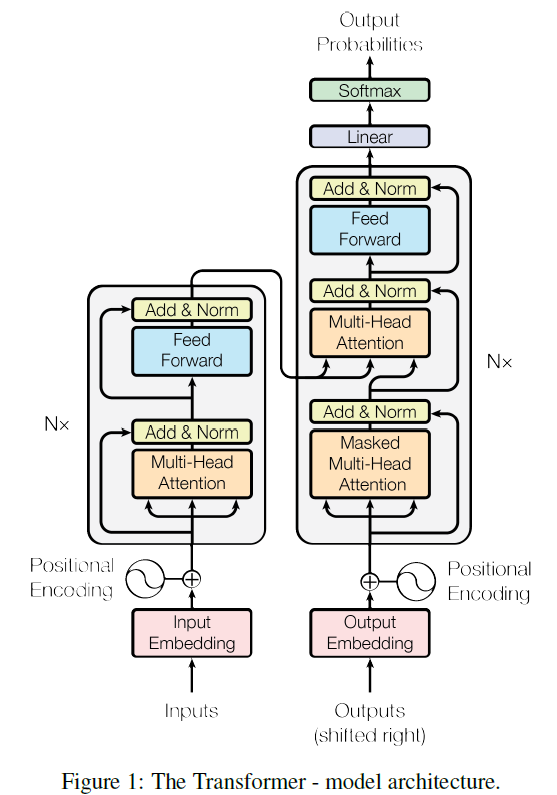
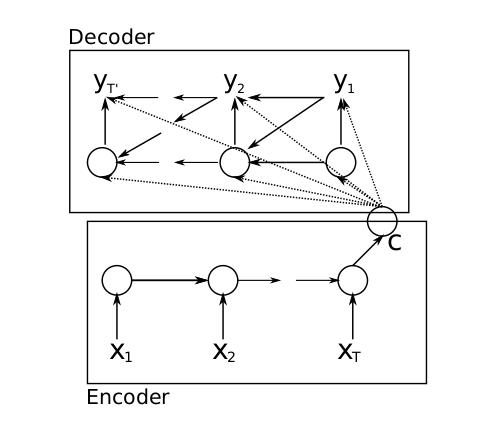
理解了multi-head attention之后,我们就可以来看看完整的transformer结构了,这里我们可以对比一下常规的encoder-decoder结构:
一般来说,原先的encoder层我们会采用LSTM来分析序列数据,而在transformer中,我们则换成multi-head attention,通过multi-head分析了词向量之后,有一个add&norm结构,其实就是残差连接(主要是增加一个x,这样求偏导的时候就避免了梯度消失)和layer normalization(归一化),再传入到一个position-wise feed-forward networks(position-wise的意思是对一个个词的multi-head attention输出,而不是一整个句子的multi-head attention输出进行分析),主要作用是提取特征和降维,这样的一个multi-head加上一个networks就构成了encoder中的一个sub-layer。而实际上我们可以在encoder中堆叠多个这样的sub-layer,从而更好地从句子中提取信息。
在原先的decoder中,我们如果要输出一个y_i,就需要历史时刻的输出和c的信息,同样,在transformer中也是需要来自encoder的信息和历史时刻的output信息,首先我们可以看看上一个时刻的output,同样会经过一个masked multi-head attention处理,masked的意思就是只处理过去的输出,避免不小心处理了未来的数据,再和encoder的输出一起输入到一个multi-head attention中,但是这里的attention结构就不再是self-attention,而是之前介绍的普通的attention结构,也就是针对两个句子(encoder输出和时刻i-1的output),分析相似度并计算输出,最后再输入到network中进行分析,并通过softmax等结构得到时刻i的输出。
通过上面的分析,就可以看到本质上来说transformer就是一个encoder-decoder模型,主要就是把RNN、CNN结构替换成multi-head attention。