seq2seq
seq2seq可以说是基于RNN提出的生成序列的模型,一般来说,对于基础的RNN我们可以输入一段序列数据得到一个输出结果,而seq2seq则可以输出一段序列结果。
seq2seq分为encoder(编码)和decoder(解码)两个过程:
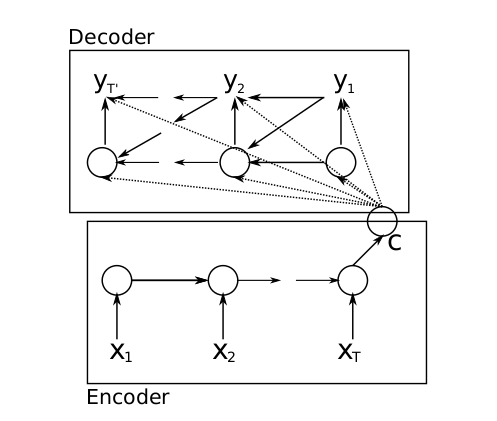
下方就是一个正常的RNN,输出C称为语义向量,用来表示输入的整个序列的含义,得到语义向量之后,就来到解码过程,把语义向量输入到另一个RNN,RNN基于语义向量再逐个输出新的序列:
可以这样理解,对于这种结构的seq2seq,它的每一个输出,由整个输入句子的意思、以及之前的输出共同决定,比如现在要把句子"today is a good day"翻译成中文,我们把语义向量输入到RNN得到第一个输出"今天",然后第二个输出是由"今天"以及语义向量共同决定的,以此类推,其实这还是RNN的正常输出。
关于这里介绍的简单seq2seq模型的缺点,主要还是RNN造成的,也就是对序列开头的数据,信息无法很好地传送到最终生成的语义向量,在学习过程中这部分数据的贡献也很少,所以有一个技巧是按反序输入序列。除此之外seq2seq还有很多变体,这里暂不介绍,在介绍了注意力机制后,再详细分析seq2seq可以怎么改进。