条件随机场
为了更好地理解条件随机场,这里主要以命名实体识别为例子,介绍如何和LSTM结合,进行NER。
首先什么是NER,就是针对一句话的每个词,都标注出它们的词性,比如输入一句"Dog play football",就输出"名词 动词 名词",一开始,我们往往会想到seq2seq这类模型,但是有一个问题,单纯的LSTM、seq2seq这类模型,输出会选择针对输入序列最优的输出,可是并没有考虑到输出序列应该满足一定的条件,比如名词后面不能接名词等等,为了从数据中分析出这类限制并应用到模型的输出中,就需要我们的条件随机场了。
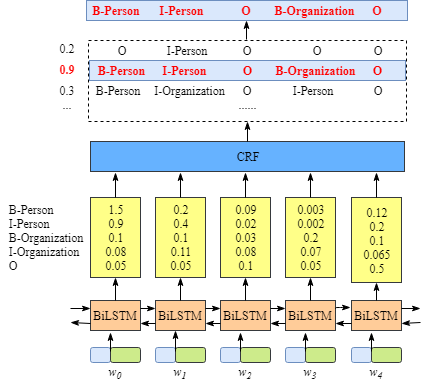
上图是一个命名实体识别的示意图,但是也可以用来说明POS,可以看到,CRF的主要作用就是针对BiLSTM的输出进一步进行分析,它主要分析的就是最终的输出之间应该有什么限制,比如它在数据中统计出名词后接名词的概率十分低,这种统计就是一种学习规律的过程,学习了规律之后,就需要构建一些函数去进行分析,调整最终的输出结果。
现在主要来分析一下CRF是如何学习这些限制条件的。首先,我们需要知道,CRF是一种无向概率图模型,也就是类似于隐马尔可夫模型,只是状态之间是相互影响的,一般的无向图有很多结构,但这里主要考虑线性链条件随机场:
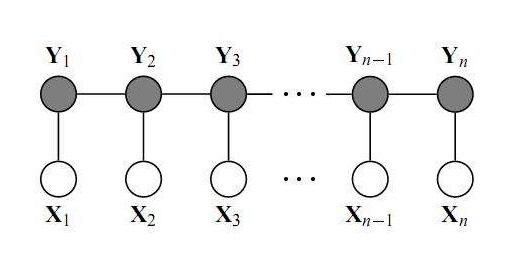
还记得之前提到,无向图的联合概率可以分解为一系列定义在最大团上的非负函数(势函数)的乘积,在这里可以看到,最大团就是每一个xy对,也就是观测变量和状态变量,比如说,这个概率可以是观测变量为Dog、状态变量为名词的概率,于是,假设我们的模型现在初始化了一个状态转移概率(或者说得分,意思是从一个状态转移到另一个状态的可能性):
同时我们的BiLSTM也输出了当前各个观测向量对应各个状态的概率(上图),那么在训练的过程中,我们就可以结合训练输出的输出计算对应的得分:
以"Dog play football"为例子,假设BiLSTM的输出是"N V N",那么我们就可以计算出模型对应的得分:
上面的start和end是句子的开头结尾标识符。另外,注意计算出来的score可以看成是一个个时刻的EmissionScore和TransitionScore对的和。
通过上面的过程,我们可以计算出得分,但为了把其转换为损失函数,我们还需要计算其他可能的序列的得分,并通过softmax函数标准化:
上式中的P_real就是训练数据中对应的输出。
让我们再看回我们计算得分的公式:
上面这样写的目的,是为了联系之前提到的计算一个无向图联合概率的方法,是计算一系列定义在最大团上的非负函数(势函数)的乘积,这里最大团就是每一个时刻的观测向量和状态向量,对非负函数就是exp,我们计算了每个时刻的势函数结果再相乘就得到了PN的形式了。
除此之外,注意到上述的损失函数我们需要最大化而不是一般情况那样最小化,所以还需要修正一下:
除此之外,也要注意一下,损失函数需要计算所有路径的得分,实际上是通过迭代过程计算,而不是真的把所有路径的得分都计算一遍再加起来,这里暂不详细介绍。
以上主要介绍了基于BiLSTM和CRF的训练过程,那么一个学习完成的模型是怎么输出的呢。首先我们要知道,这个模型主要学习的有两个部分,一个是BiLSTM,一个是CRF中的状态转移概率,假设目前已经学习了所有参数,那么模型是怎么处理输入得到输出的呢。
之前在介绍隐马尔可夫模型时就介绍了维特比算法,它是一种解码算法,可以根据观察序列和状态转移概率去分析隐藏状态,实际上我们应用CRF时也是一种解码过程,把BiLSTM的输出看作观测向量,应用维特比算法就可以解出CRF的隐藏状态,也就是我们最终的输出。
最后,作为总结,用通俗的语言从几个角度再重新分析一下条件随机场。
第一点,条件随机场作为概率图模型,和隐马尔可夫模型一样,都可以用于序列标注,它们最主要的区别是一个是无向图模型一个是有向图模型,简单来说就是一个认为不同状态之间是相互影响的,另一个则认为不同状态之间是单向影响的,而这种区别,在公式上就体现在它们在计算一个序列出现的概率时,隐马尔可夫模型是用条件概率按序列顺序逐个相乘,而条件随机场则是分解为一个个最大团,应用势函数和softmax函数计算概率,其中并不需要按顺序计算,这里就是两者最大的区别。
第二点,关于BiLSTM-CRF模型,简单来说,在序列分析过程中,重点的改进在于CRF的应用,它分析了输出序列之间的转换概率,通过这个概率去表示不同状态之间的转换的合理性,比如在词性分析中,名词后接名词的概率很低,这个现象就可以通过转换概率较低反映出来。
第三点,在模型的应用过程中利用的维特比算法,它在隐马尔可夫模型中也有应用到。我个人认为,这个算法的核心在于求出当前情况下最优的路径,所谓当前情况就是指状态转移概率和观测向量,条件随机场和隐马尔可夫模型虽然不同,但这种区别仅仅反映在状态转移概率上,在求最优路径(隐藏状态序列)时,两者是具有一直目的(使得输出序列概率最大)。