多层感知器
在介绍单层感知器的时候,我们提到对于非线性可分问题,单层感知器是很难解决的,比如下面这个例子:
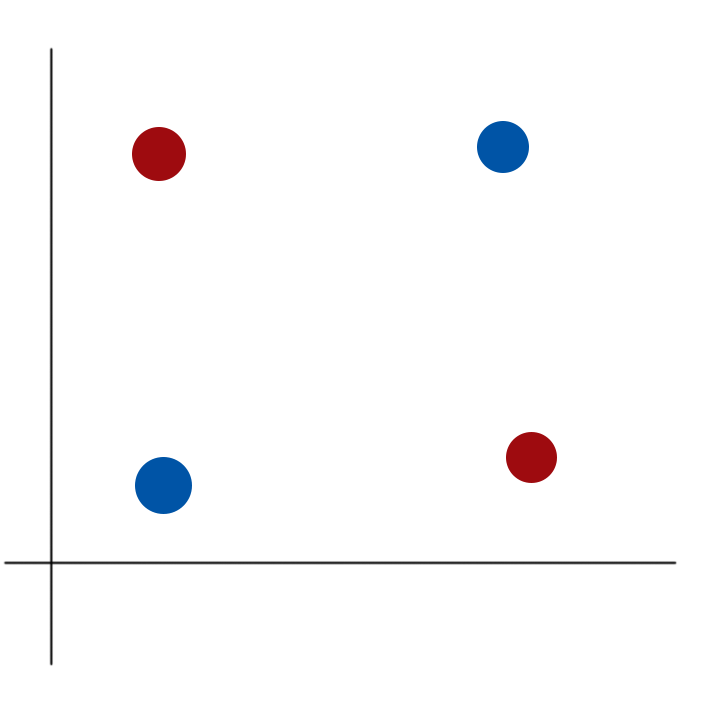
很简单的一个分布,但事实上就是无法用直线进行分类,后来就出现了多层感知器,主要改变的地方是把第一层的感知器的输出作为第二层感知器的输入,即使只是简单添加一层感知器,也足以解决xor问题,关键的原因是,多了一层感知器,就像对原来的输入做了一个映射,第一层感知器的目的是对输入进行映射使得数据在新的空间能够线性可分,然后我们再利用第二层感知器对数据进行分类,我们通过训练模型,使得第一层感知器能更好地重新映射原输入,第二层感知器能更好地分类。
接下来结合下图介绍一下多层感知器的一些术语和结构。
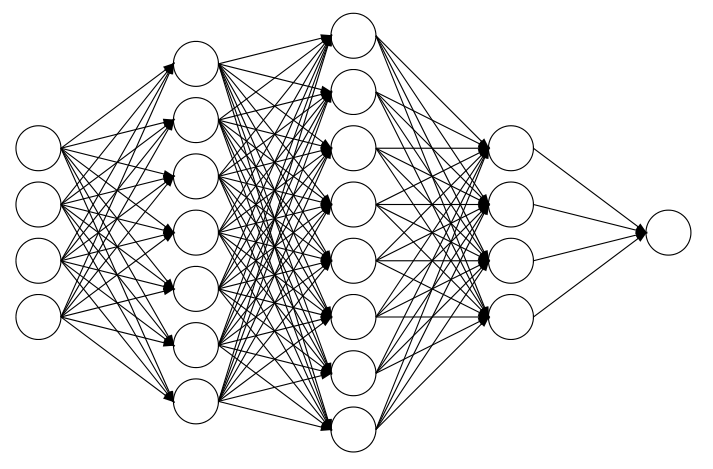
多层感知器,又叫深度前馈网络、前馈神经网络。最左边的是输入层,就是我们的输入数据,最右边的是输出层,中间的就是隐藏层(因为训练数据并没有直接表明隐藏层的每一层的所需输出),实际上就是由感知器构成。从现在开始,感知器就开始称为神经元,而这整个包含了输入层、隐藏层和输出层的结构就是大名鼎鼎的神经网络。可以看到相邻层之间的神经元是全连接的。
多层感知器的学习过程也是和感知器接近,主要都是计算训练数据的输出,根据预测输出和实际输出之间的差异去调整神经元的权值和阈值,不断迭代训练直到误差小于一定范围。同时也可能有一种情况,就是迭代次数已经很大可是模型依然无法得到很好的训练效果,这时我们就需要调整模型的超参数,比如神经元的数量、隐藏层的层数等等。基本上,这个过程和之前的线性回归等机器学习过程是一致的。