用GLM进行数据分析(上)
在这里,我通过我的作业来介绍一下如何用GLM进行数据分析(这里主要用R进行分析),不过还没拿到答案,所以也不确定结果是否正确,不论怎样,介绍一下整个分析的思路也足够了。

以上是数据的一些介绍,简单来说就是分析急诊室就诊次数和一些变量之间的关系吧,首先我们来分析一下这些数据的大致情况:
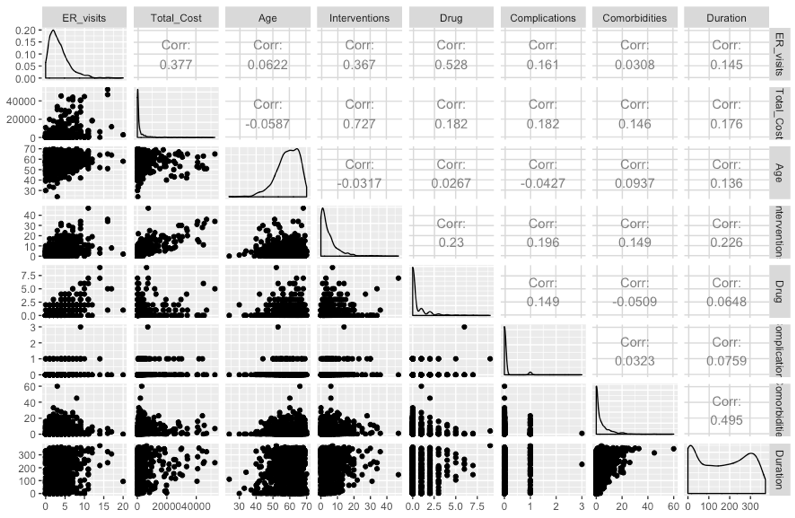
可以看到,一大堆变量,包括响应变量都是右偏的,一般来说这时候我们就可以对他们应用log transformation(这里需要注意,因为变量具有较多的0值,所以采取log(x+1)做变换,这也是一个小技巧)来缓和这种现象,我们可以通过直方图来观察转换前后的状况,同时也观察有没有需要剔除极端数据。
在观察直方图的过程中,也发现了complication这个变量其实是严重的不平衡。一般来说,对这种数据有很多处理方法,我可能比较极端一点,喜欢直接剔除它,当然,也不是说不要就不要的,主要还是要分析complication对于0和1这两种情况,我们的ER_visits有没有明显的区别,所以我们可以通过图表画出来:
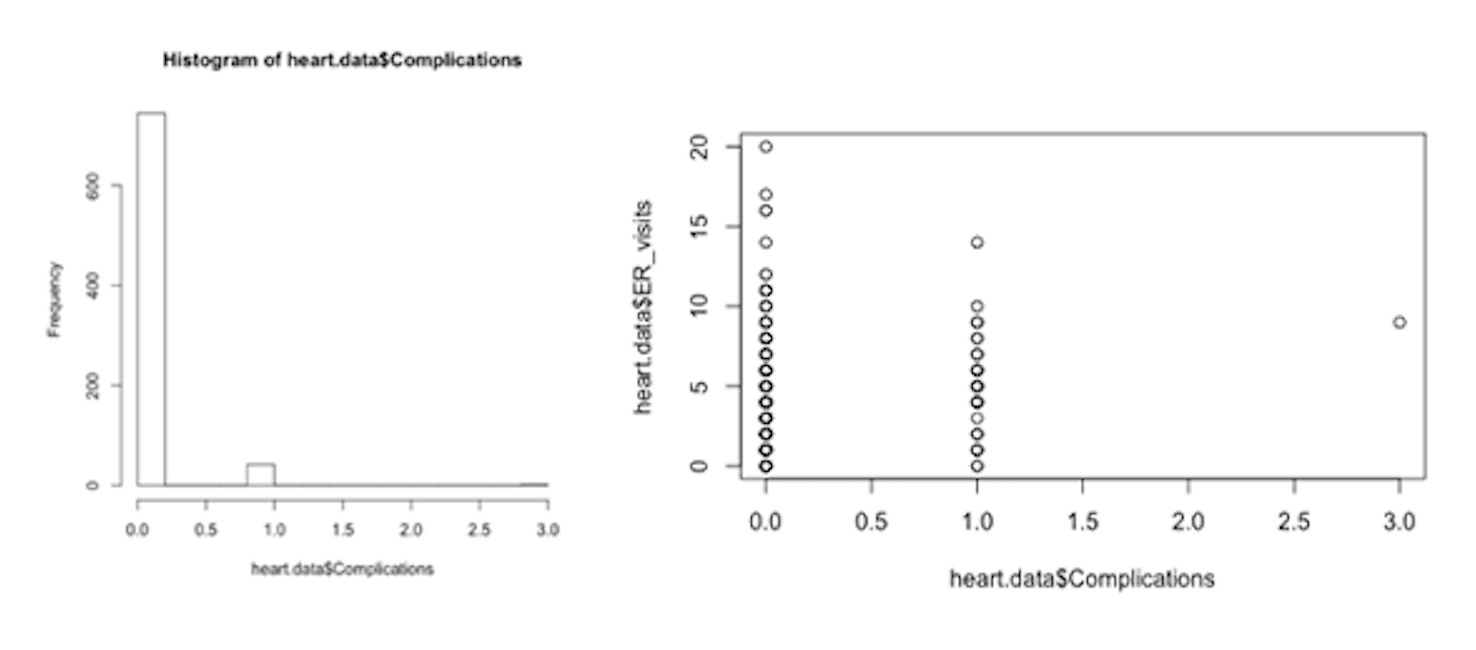
可以看到,0和1的ER_visits其实分布都比较接近,也就是说不会因为complication的不同取值而导致响应变量有明显变化,所以我这里选择剔除这个变量。
除此之外,我们还注意到对于drug和comorbidities这两个变量,即使使用了log变换,结果还是右偏:
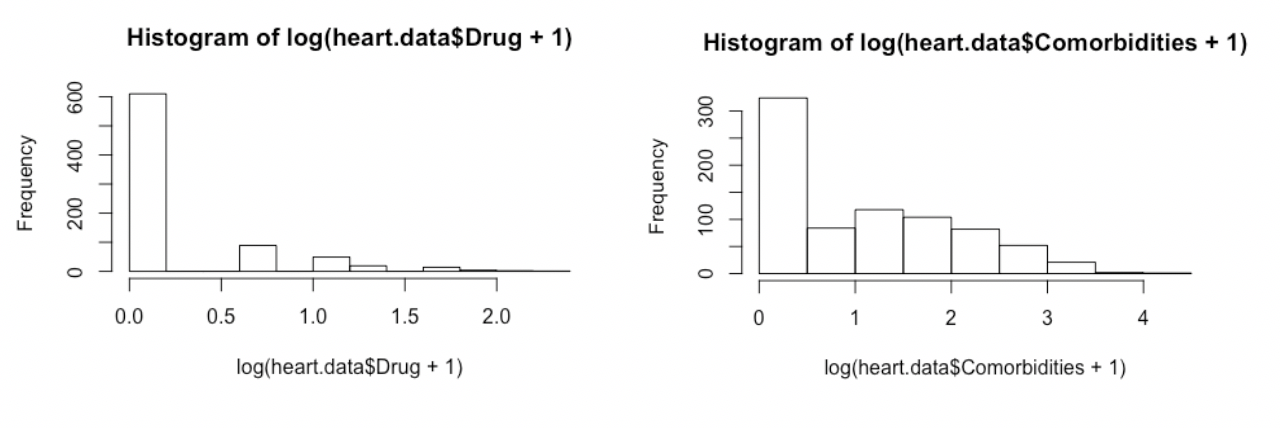
这种情况下,我选择直接对他们进行二分类,把大于0的数据分为一类,用1表示,等于0的用0表示。然后,我们再重新观察数据:
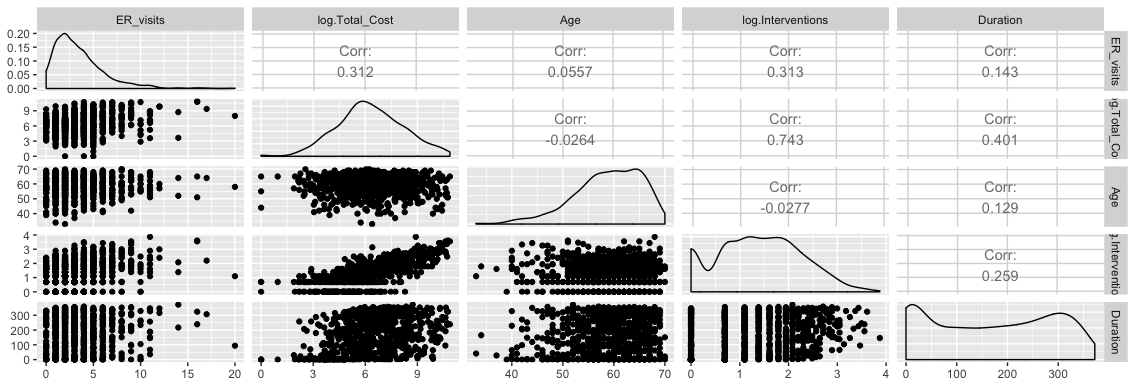
经过初步处理,数据的分布就比一开始好很多了。我们也可以隐约看出ER_visits和total_cost、age之间的正比关系,但是,也要注意到,这时候total_cost和interventions之间的相关系数较大,也就是说,在构建模型的时候,我们只能保留两者其中之一。
以上主要是针对数值数据的预处理,接下来是对类别数据的预处理,首先我们通过表格观察数据是否严重不平衡:

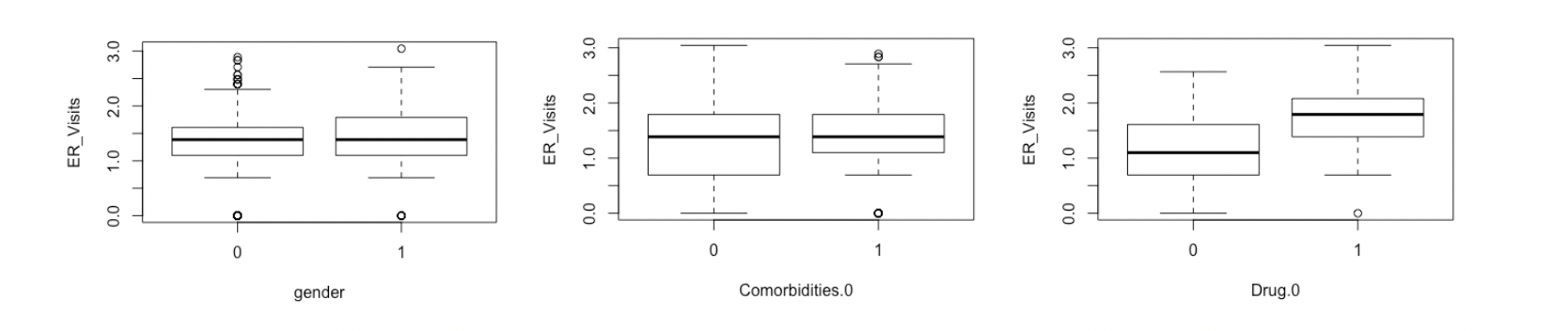
在这里没有特别需要处理的数据,然后我们可以通过箱线图,初步探索一下各个变量和响应变量之间的关系:
到目前为止,我们就基本完成了数据的预处理了,接下来,就可以正式构建一个GLM模型了。